Abstract

Tuning-free diffusion-based models have demonstrated sig- nificant potential in the realm of image personalization and customiza- tion. However, despite this notable progress, current models continue to grapple with several complex challenges in producing style-consistent image generation. Firstly, the concept of ’style’ is inherently underde- termined, encompassing a multitude of elements such as color, material, atmosphere, design, and structure, among others. Secondly, inversion- based methods are prone to style degradation, often resulting in the loss of fine-grained details. Lastly, adapter-based approaches frequently re- quire meticulous weight tuning for each reference image to achieve a bal- ance between style intensity and text controllability. In this paper, we commence by examining several compelling yet frequently overlooked observations. We then proceed to introduce InstantStyle, a framework designed to address these issues through the implementation of two key strategies: 1) A straightforward mechanism that decouples style and con- tent from reference images within the feature space, predicated on the assumption that features within the same space can be either added to or subtracted from one another. 2) The injection of reference image features exclusively into style-specific blocks, thereby preventing style leaks and eschewing the need for cumbersome weight tuning, which often charac- terizes more parameter-heavy designs.Our work demonstrates superior visual stylization outcomes, striking an optimal balance between the in- tensity of style and the controllability of textual elements.
Method
Separating Content from Image. Instead of employing complex strategies to disentangle content and style from images, we take the simplest approach to achieving similar capabilities. Compared with the underdetermined attributes of style, content can usually be represented by natural text, thus we can use CLIP’s text encoder to extract the characteristics of the content text as content epresentation. At the same time, we use CLIP’s image encoder to extract the features of the reference image as we did in previous work. Benefit from the good characterization of CLIP global features, after subtracting the content text fea- tures from the image features, the style and content can be explicitly decoupled. Although simple, this strategy is quite effective in mitigating content leakage.

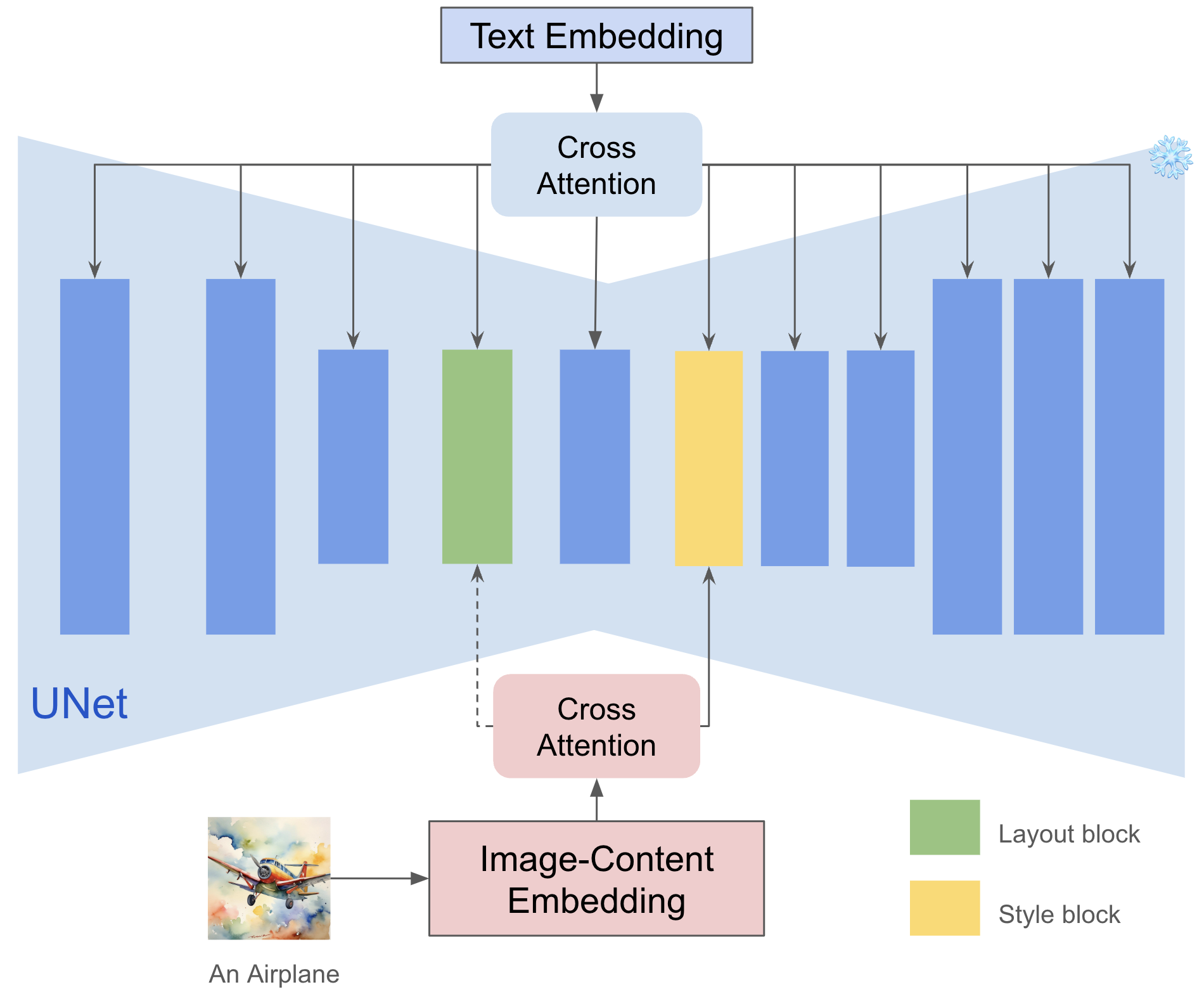
Injecting into Style Blocks Only. Empirically, each layer of a deep network captures different semantic information the key observation in our work is that there exists two specific attention layers handling style. Specifically, we find up blocks.0.attentions.1 and down blocks.2.attentions.1 capture style (color, material, atmosphere) and spatial layout (structure, composition) respectively. We can use them to implicitly extract style information, further preventing content leakage without losing the strength of the style. The idea is straightforward, as we have located style blocks, we can inject our image features into these blocks only to achieve style transfer seamlessly. Furthermore, since the number of parameters of the adapter is greatly reduced, the text control ability is also enhanced. This mechanism is applicable to other attention-based feature injection for editing or other tasks.

Overview of IP-Adapter with InstantStyle. There are 11 transformer blocks with SDXL, 4 for downsample blocks, 1 for middle block, 6 for upsample blocks. We find that the 4th and the 6th blocks are corresponding to layout and style respec- tively. Most time, the 6th blocks is enough to capture style, the 4th matters only when the layout is a part of style in some cases. In addition, you can also optionally use the characteristics of CLIP to explicitly subtract content from the feature space.
▶ Text-to-Image Generation with Style Reference using Subtraction





▶ Text-to-Image Generation with Style Reference using Style Block

